Review Materi Data Structure
Nama : Dikky Larson
NIM : 2301853930
Pada kesempatan kali ini , saya akan mereview apa yang saya telah dipelajari sejauh ini. Langsung saja kita bahas satu per satu topik mengenai data structure ini 😊.
NIM : 2301853930
Pada kesempatan kali ini , saya akan mereview apa yang saya telah dipelajari sejauh ini. Langsung saja kita bahas satu per satu topik mengenai data structure ini 😊.
Linked List
1. Definisi
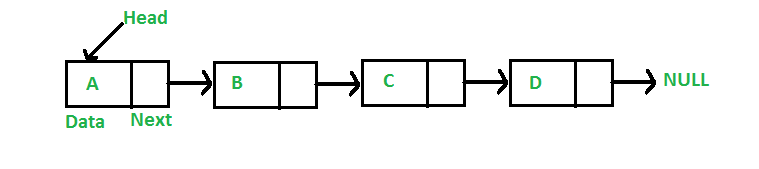 |
| 1.1. Linked List illustration - https://www.geeksforgeeks.org/wp-content/uploads/gq/2013/03/Linkedlist.png |
Linked List merupakan sebuah metode penyimpanan koleksi secara dinamis (dynamic collection) yang digunakan untuk mempermudah penyisipan data diantara kumpulan data yang telah ada.
Meski memiliki konsep yang mirip dengan Array, Linked List memiliki keuntungan dalam penyisipan dan pembuangan data dibandingkan Array. Hanya saja, kelemahannya terletak pada cara mengakses data didalamnya. Pada konsep Linked List, pengaksesan data didalamnya harus secara berurutan dari awal, hal ini dikarenakan linked list tidak mengenal indeks seperti Array.
Jika pada Array dikenal istilah index (indeks), maka Linked List mengenal istilah nodes atau titik. Hal ini terjadi karena Linked List menggunakan alokasi memori yang selalu berbeda dan menghubungkannya dengan memory address yang lain, sehingga kita akan lebih mudah memahaminya dengan nodes.
Setiap Linked List akan selalu memiliki head node, yang berfungsi untuk menunjukkan node awal, dan memiliki tail node, yang akan menunjukkan akhir dari Linked List. Untuk tail node biasanya akan diisi dengan NULL.
2. Tipe
Tipe Linked List yang umum dikenal ada tiga, yaitu:
- Single Linked List
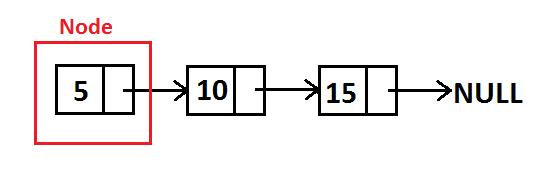
2.1. Single Linked List - https://socs.binus.ac.id/files/2017/03/rini-1.jpg Single Linked List menggunakan 2 buah fields. Pertama, adalah field untuk data yang ditampung. Kedua adalah field yang ditujukan sebagai link (koneksi) untuk node yang berikutnya. - Doubly Linked List

2.2. Doubly Linked List - https://media.geeksforgeeks.org/wp-content/cdn-uploads/gq/2014/03/DLL1.png Double/Doubly Linked List akan menggunakan satu tambahan field yang ditujukan untuk memuat link dari node sebelumnya. - Circular Linked List

2.3.1. Circular Single Linked List - geeksforgeeks.org/wp-content/uploads/cll_orig.gif 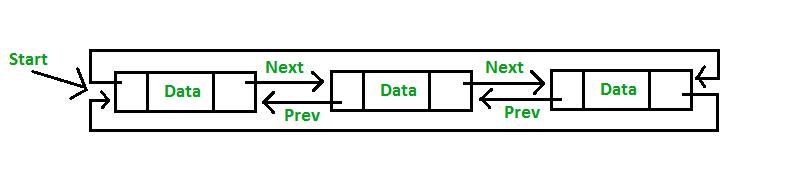
2.3.2.Circular Doubly Linked List - https://media.geeksforgeeks.org/wp-content/uploads/Circular-doubly-linked-list.png Kedua jenis Circular Linked List diatas memiliki ciri yang sama seperti tipe-tipe Linked List sebelumnya. Perbedaannya hanya terletak pada tail node. Tail node pada Circular Linked List akan berisi link ke data awal atau head node.
3. Metode Penyisipan dan Penghapusan Data
Perlu diketahui bahwa bahasa C adalah acuan dalam penyampaian materi ini dan penyampaian terbatas hanya pada Single Linked List dan beberapa contoh saja. Untuk Double Linked List hanya perlu penambahan field untuk link ke node sebelumnya.
- Pembuatan struct node

3.1. Initializing node struct - Penyisipan data

3.2. Penyisipan data di akhir - Penghapusan data

3.3.1. Penghapusan data diantara awal dan akhir 
3.3.2. Penghapusan data di awal Hashing and Hash Table
Pendahuluan
Hashing adalah sebuah metode/cara menyimpan dan mengambil data secepat mungkin. Jika kita menggunakan loop untuk mengambil suatu data dari index tertentu, maka akan diperlukan waktu compile sebanyak ON dikarenakan kita harus mencari dari awal hingga akhir.Hal itu tidak terjadi pada hashing sebab hashing menggunakan metode penyimpanan dimana indeksnya merupakan hasil dari manipulasi string yang kita input. Sehingga ketika kita melakukan pencarian, system akan bisa langsung menunjuk pada indeks yang menjadi tempat dimana data tersebut disimpan.Hash Function
Untuk mengubah/memanipulasi string menjadi indeks hash-table, diperlukan hash function. Berikut ini beberapa contoh dari hash function:- Mid-square

1.1. Mid-square function, sumber: binusmaya.binus.ac.id Mid-square merupakan fungsi hash dimana kita akan memangkatkan value awal, lalu mengambil angka tengah sebagai indeks untuk hash table. Jika valuenya berupa string, maka terlebih dahulu kita mengubahnya ke dalam number (int) menggunakan ASCII atau metode lain yang kita ketahui. - Division
Dalam division function, kita mengubah value dari data yang ingin dimasukkan menggunakan modifier. Sangat dianjurkan untuk menggunakan bilangan prima -sesuai dengan jumlah table yang ingin dibuat- sebagai modifier untuk menghindari terjadinya collision (data bertumpuk dalam satu indeks table).
2.1. Division function - Folding
Folding adalah teknik hashing dengan langkah pertama yaitu, membagi value menjadi beberapa bagian, menjumlahkannya, baru memasukkannya sesuai dengan size table yang sudah dibuat/ditentukan.
3.1. Folding function, sumber: binusmaya.binus.ac.id - Digit Extraction
Digit extraction adalah metode dimana kita hanya mengambil beberapa digit dalam sebuah value sebagai hashkey untuk hash table yang kita buat.
4.1. Contoh Digit Extraction Logic, sumber: binusmaya.binus.ac.id - Rotating Hash
Rotating Hash merupakan metode hash yang menggunakan salah satu function diatas (mid-square atau division), lalu key yang sudah ada kemudian dirotasi digitnya.
Contoh:
hashkey yang sudah kita dapatkan dari salah satu function = 20021
hashkey kemudian dirotasi sesuai yang kita inginkan, misalnya menjadi = 12002 (di-flip)
Collision
Collision adalah kondisi dimana value yang kita masukkan bertabrakan dengan value yang sebelumnnya di satu indeks hash table yang sama.Misal kita akan menyimpan value atan dan acos. Jika kita hanya hashing pada huruf pertama menggunakan division, maka indeks atan dan acos akan menempati bagian indeks yang sama. Hal ini tentu akan menimbulkan issue karena kemungkinan data akan ter-overwrite.Ada dua solusi untuk mengatasi permasalahan ini, diantaranya:- Linear Probing
Linear probing adalah cara pertama untuk menghidari collision dengan cara memindahkannya ke indeks yang masih kosong di setelah/sebelum indeks hash. Hal ini memiliki kelemahan, salah satunya adalah terbatasnya spare indeks ,jika data yang dimasukkan semakin banyak, maka compilation time akan semakin lama karena sudah banyak indeks hash table yang penuh dan jika semua table sudah penuh, maka data tidak akan masuk atau terbuang.
1.2. Penggambaran logika Linear Probing, sumber: binusmaya.binus.ac.id - Chaining
Chaining merupakan teknik penambahan memory allocation menyamping jika terjadi collision di suatu indeks hash table. Dengan penambahan penampung data secara menyamping, kita tidak perlu khawatir akan limitasi data yang ditampung.
2.2.Penggambaran logika Chaining, sumber: binusmaya.binus.ac.id
Implementasi Hash Table dalam Blockchain
Hash table pada blockchain digunakan untuk mengambil transaction pada suatu block menggunakan key yang ada.Selebihnya mengenai blockchain dapat dibaca disini: http://ceur-ws.org/Vol-2334/DLTpaper4.pdfTree dan Binary Tree
Pengenalan Tree
Tree adalah struktur data yang bersifat non-linear yang menggambarkan hubungan hierarki antar objek data.Konsep Tree
- Objek data yang berada di puncak/paling atas disebut root.
- Node yang berada diatas node yang lain disebut parent/ancestor dari node tersebut.
- Node yang berada di bawah node yang lain disebut child/descendant node dari parentnya.
- Garis yang menghubungkan parent dengan child node disebut edge.
- Total subtree/cabang disebut degree.
- Jumlah maksimum degree dari sebuah node disebut height/depth.
Binary Tree
Binary tree adalah jenis tree dimana tiap-tiap node memiliki paling banyak dua degree (dua child node).Jenis Binary Tree
Beberapa jenis binary tree, diantaranya adalah:- Perfect Binary Tree
Perfect binary tree adalah kondisi dimana degree dari tiap node di setiap level memiliki jumlah yang sama.
1.1. Perfect Binary Tree, sumber: https://i.stack.imgur.com/EHqzp.png - Complete Binary Tree
Complete binary tree adalah tree dimana setiap node di tiap level, kecuali kemungkinan yang terakhir, memiliki data objek. Semua perfect binary tree adalah complete binary tree.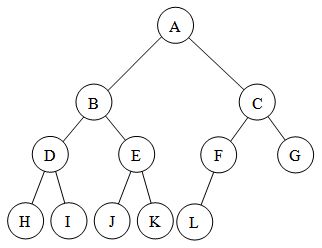
2.1. Complete Binary Tree, sumber: https://web.cecs.pdx.edu/~sheard/course/Cs163/Graphics/CompleteBinary.jpg - Skewed Binary Tree
Skewed binary tree adalah jenis binary tree dimana degree dari tiap node di tiap level hanya berjumlah satu.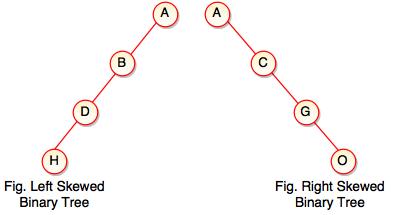
3.1. Left and Right Skewed Binary Tree, sumber: https://www.tutorialride.com/images/data-structures/skewed-binary-tree.jpeg - Balanced Binary Tree
Balanced binary tree adalah kondisi dimana jumlah perbedaan antara subtree kiri dan subtree kanannya paling banyak berjumlah satu.
4.1. Balanced Binary Tree, sumber: https://upload.wikimedia.org/wikipedia/commons/thumb/0/06/AVLtreef.svg/251px-AVLtreef.svg.png
- Mid-square








Binary Search Tree
Pengertian
Binary Search Tree (BST) adalah jenis tree yang dapat mempercepat proses pencarian (searching), pengurutan (sorting), dan penginputan/penghapusan data (insertion/deletion).
Dapat disebut sebagai Sorted Binary Tree.
Konsep
Jika data yang akan masuk bernilai lebih kecil dari suatu node X, maka data akan masuk ke subtree bagian kiri dari X.
Sebaliknya, jika data yang akan masuk bernilai lebih kecil dari suatu node X, maka data akan masuk ke subtree bagian kiri dari X.
Untuk konsep dasar dari tree, dapat dilihat di atas 😊
Metode / Operations
- find(value)

- insert(value)

- remove(value)
ada beberapa cara dalam menghapus / remove suatu node di dalam BST, yaitu:


- Jika node berada di leaf, maka tinggal remove saja.
- Jika node memiliki 1 child node, maka hapus node dan sambung child-nya dengan parent dari node yang dihapus sebelumnya.
- Jika node memiliki 2 child node, maka ganti node yang akan dihapus dengan child paling kanan di subtree kiri (bisa juga menggunakan child paling kiri di subtree kanan).

Comments
Post a Comment